AI 基础概念
可跳过. 虽然不了解也能用, 但简单知道也有所帮助.
Token
Token 是 AI 和你的对话内容计数单位. 通常把一个词记作一个Token, 而不是一个汉字或字母.
1 个英文字符 ≈ 0.3 个 token, 1 个 token 大约为 4 个英文字符或 0.75 个英文文本单词.
1 个中文字符 ≈ 0.6 个 token.
《哈利波特与魔法石》全文约 8 万个英文单词, 大约 12K token.
下面这张图就是一个 Token 划分的例子.
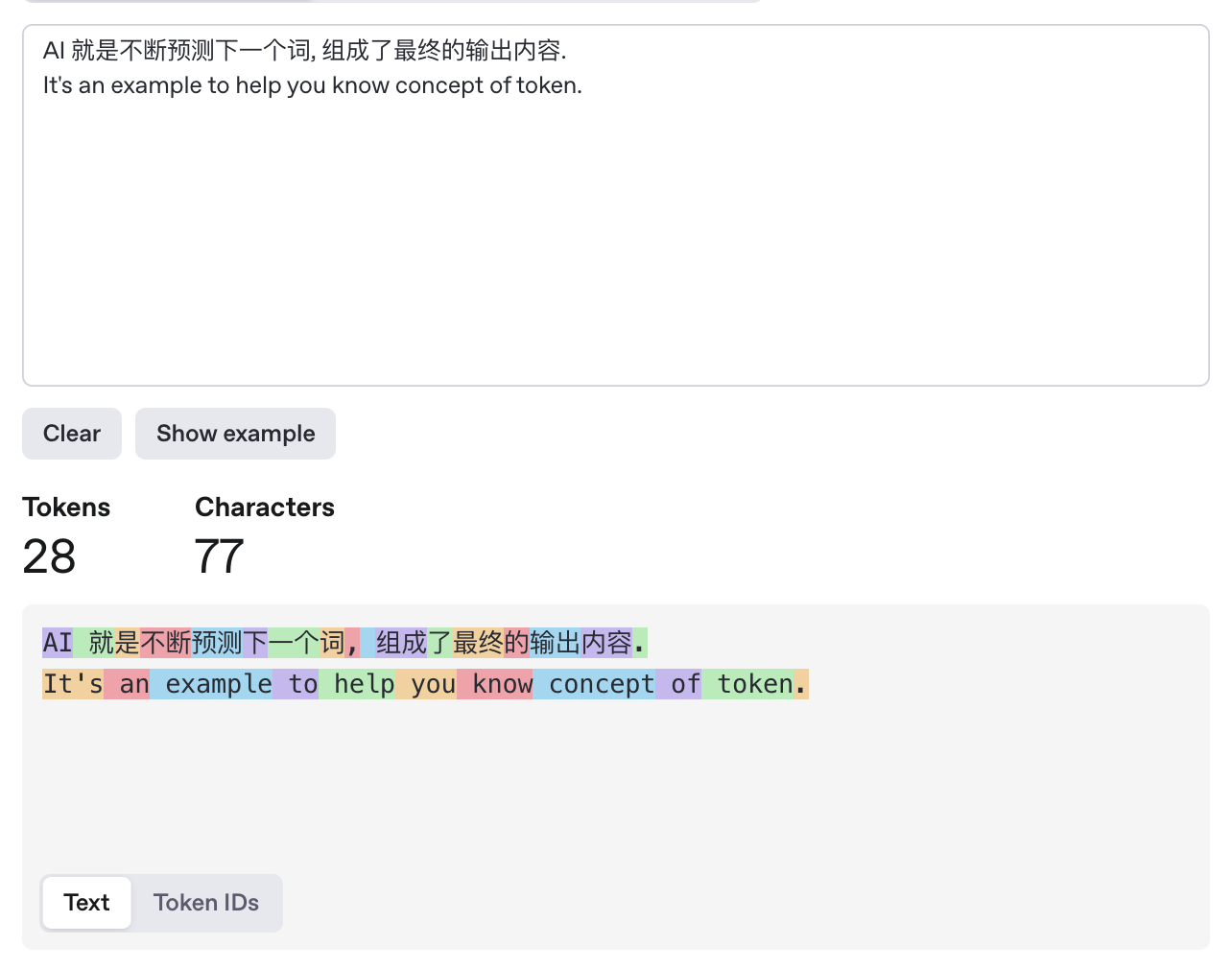
输入给 AI 的和 AI 输出给你的 Token 越多, 那么对应的费用也就越多.
所以有时候要精炼下你的语言, 也要让 AI 少说点废话.
上下文
你可以理解为"记忆". 你和 AI 的每一轮对话, 你上传的文件都会作为 AI 的上下文. 但是 AI 的上下文是有限的, 也就是他能记住的东西是有限的. 如果你和他的对话很长/你传的文件很长, AI 就会记不住你说的话/找不到文件中的内容.
但上下文也并不是越大越好, AI 记得东西记得太多了, 也就会记错些东西.
常见的上下文大小一般有: 64K, 128K, 1M.
多模态
如果你有用过 DeepSeek 的软件, 你会发现他不能上传图片.
这是因为 DeepSeek 的模型不支持多模态, deepseek-v3和deepseek-r1都是文字模型, 只能进行文字的输入输出.
多模态 就是指 AI 能接受的输入类型, 也就是 AI 的感觉器官.
常见的多模态有文字+图片, 文字+语音, 文字+图片+语音.
文字: 会读会写.图片: 理解图片, 会识物.语音: 会听会说.
模型类型
非推理模型
和推理模型相对, 不会思考. 直接给你输出.
e.g.
deepseek-v3推理模型
模型会先对你的输入进行思考推理, 得到更加合理的逻辑后, 再给你输出.
既然相比非推理模型多了思考, 那输出思考的部分也会增加成本, 获得更好的效果.
e.g.
deepseek-r1
模型参数量
有的模型名称后面会带有类似8B, 这样数字+B的形式. 这里是指的参数量, 8B即 8 Billion, 8 亿参数. 参数越大, 模型也就越好.
幻觉
有时 AI 会输出莫名其妙的内容,一本正经地跟你胡说八道, 这就是幻觉.
大概的原因就是大模型预测下一个最有可能出现的词, 然后一个接一个地组成句子, 就出现了句子看起来很通顺, 但并没有逻辑.
所以不能完全相信 AI 生成的内容, 如果要使用的话记得自己检查一下.